Speech To Text Service Summary
Automatic Speech Recognition (ASR) research has achieved significant advancements in recent years, particularly for high-resource languages like English. However, a significant disparity exists in the availability of ASR models for low-resource languages. Bengali, the 7th most spoken language globally with over 234 million native speakers, exemplifies this gap. This lack of dedicated tools and resources for Bengali hinders the development of AI-powered solutions in crucial sectors like healthcare.
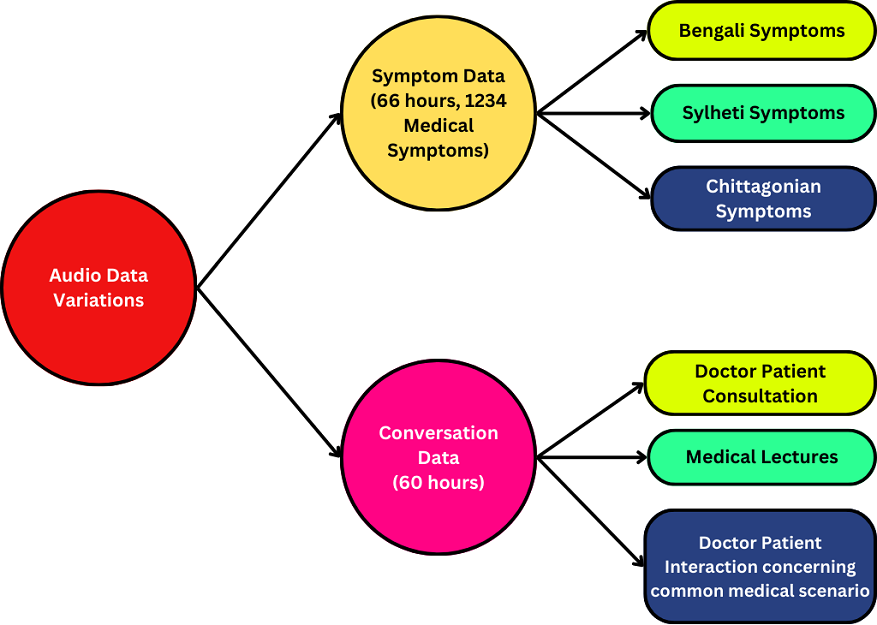
Fig: Audio Data Variations
We primarily offer two categories of Audio Data Collection.
- Symptom Data, where each speaker articulates a single symptom
- Conversation Data, where dialogues between Doctors and Patients and Medical Lectures are recorded.

Fig: Symptom Data Variations
The symptom data collected for Bengali amounts to 30 hours, while for Sylheti it totals 30 hours, and for Chittagonian, it is 6 hours. In total 66 hours of symptoms data was collected

Fig: Conversation Data Variations
On the other hand, the conversation data consisted of Doctor-Patient consultations (30 hours), Medical Lectures focusing on Cardiovascular Health (20 hours), and simulated Doctor-Patient interactions covering common medical scenarios (10 hours). In total 60 hours of conversation data was collected
Performance
Currently, our ASR has an average accuracy of 79%